Главный управляющий подразделением CUDA в компании NVIDIA, Сэнфорд Рассел, в интервью с журналистами ресурса Fudzilla отметил, что его команда работает над методами ускорения поиска вирусов с помощью видеокарт.
Новости по теме «CUDA может ускорить поиск вредоносных программ»
NVDIA обещает 10% прирост производительности CUDA благодаря LLVM
Разработчик микропроцессоров, компания NVIDIA, обновила CUDA библиотеку базовых классов для объектно-ориентированного GPGPU программирования, включив в неё для увеличения производительности низкоуровневую виртуальную машину — low level virtual machine (LLVM).
В прошлом году компания объявила о значительных изменениях в их проприетарном программном фреймворке CUDA, а несколько дней назад выпустила первую версию изменения, которое включает компилятор LLVM. По утверждению NVIDIA, LLVM обеспечит «постоянное 10% ускорение в производительности приложений».
Кроме того, что NVIDIA теперь восхваляет мощь LLVM компилятора, фирма также предлагает виртуальный профилировщик, который поможет программистам оптимизировать их код. Суть в том, что программирование для GPGPU в большинстве случаев требует значительных оптимизаций, чтобы выжать каждую последнюю каплю скорости из GPU.

Кроме LLVM компания расширила библиотеку обработки сигналов. Обычно самостоятельный цифровой сигнальный процессор используется исследователями для симуляции определённых нагрузок, но с растущей библиотекой обработки сигналов некоторые нагрузки могут быть запущены на графической платформе NVIDIA с включённым CUDA.
Но пока NVIDIA наслаждалась популярностью CUDA в исследовательском сообществе, на горизонте появился серьёзный конкурент в лице OpenCL — открытого языка GPGPU вычислений. Тем не менее, NVIDIA утверждает, что им абсолютно безразлично какой именно язык используют программисты, до тех пор, пока они используют их графические платформы, продвигая CUDA в качестве отличного способа улучшения продаж GPU продуктов компании.
Глава NVIDIA поделился видением будущего GPGPU-технологий
CUDA останется основным API, поддерживаемым NVIDIA.
Глава NVIDIA Jen-Hsun Huang в интервью британскому отделению издания ZDNet ответил на вопросы о будущем GPGPU-технологий. Мы приводим выдержку высказанных им суждений:

- NVIDIA активно поддерживает открытый стандарт OpenCL, тем более что Khronos Group в настоящее время возглавляет сотрудник компании. NVIDIA первой реализовала поддержку OpenCL, причём она всё еще считается лучшей в отрасли, и будет поддерживать OpenCL и дальше.
- Технологии меняются очень быстро, производительность увеличивается четырёхкратно каждые два года, новые функции внедряются постоянно. В силу этого NVIDIA концентрируется на CUDA, не желая немедленно «выкатывать» новый общий стандарт. Тем более, что OpenCL такого внимания и не требует — там есть множество людей, в том числе из IBM, AMD, Intel, и NVIDIA не нужно тащить всё в одиночку.
- CUDA получил большее распространение, чем OpenCL, в силу большей истории и инвестиций в разработку, большего числа работающих с ним людей, большего качества инструментов разработки, компилятора, надёжности рабочей среды.
- NVIDIA не пытается каким-то способом полностью заменить CPU или нарушить их работу. Операционные системы и офисные приложения будут продолжать работать на CPU — но будет возможно прибегнуть к силе GPU для того, чтобы «проломить» определённые задачи.
- Будущее за гетерогенной средой, в которой встретятся нарастившие мощь векторной обработки данных CPU и GPU с параллельной обработкой данных, научившиеся решать более сложные типы задач. В такой среде все приложения будут работать невероятно быстро.
- Сейчас ситуация с приложениями такая, что они не работают, не работают, а потом раз — и работают очень быстро. Технологии вроде виртуальной памяти и синхронизации данных в памяти облегчат программирование. В целом будет лучше, если приложения будут работать сразу, пусть и лишь в три раза быстрее. Затем можно будет заниматься оптимизацией.
- Сейчас графические процессоры лучше всего работают с одним приложением, так устроен их конвейер, следствие stateful-подхода. К примеру, одна большая программа исполняется на многих GPU. В будущем будет иная ситуация: множество приложений, использующих один GPU. NVIDIA работает над тем, чтобы обеспечить возможность использования обоих подходов.
- В будущей архитектуре сервер с одним модулем Tesla сможет одновременно предоставить игровой ускоритель для сеанса геймера, Quadro-ускоритель для сеанса дизайнера автомобиля и GPGPU-ускоритель для сеанса высокопроизводительных вычислений. Можно будет одновременно заниматься вычислениями и визуализацией в отдельном «облаке», получая высококачественную картинку на экран компьютера, планшетного ПК или телефона.
- Ключ к созданию подобных архитектур — отказ от копирования данных туда-сюда. NVIDIA совместно с InfiniBand разрабатывает решение, которое позволит избежать постоянного копирования данных из системной памяти в видеопамять и обратно. Это позволит частично снять остроту проблемы полосы пропускания каналов связи, хотя всё равно всегда будут требоваться как можно более быстрые методы передачи данных.
Будем надеяться, что в погоне за раскрывающими перспективами облачных сред и распределённых вычислений компания не забудет совсем про сегмент, собственно, видеокарт для конечных ПК.
Релиз Parallel Nsight 1.5 и обновлённые руководства по стерео
Новая версия среды разработки графических и GPGPU-приложений.

NVIDIA выпустила версию 1.5 своего набора средств для разработки графических и GPGPU-приложений Parallel Nsight, ранее известного как Nexus. Новая версия поддерживает интеграцию в Microsoft Visual Studio 2010, совместима с проектами CUDA Toolkit 3.2, содержит обновлённый отладчик CUDA-программ с поддержкой новых видеокарт GeForce и Quadro на базе Fermi, полностью поддерживает Direct3D 11 и DirectCompute и содержит ряд других изменений. Загрузить дистрибутив комплекта можно с сайта NVIDIA для разработчиков по ссылкам ниже:
- Для Windows 32-bit (~170 Мб)
- Для Windows 64-bit (~290 Мб)
Системные требования:
- Операционная система Windows Vista/7/2008
- Двуядерный процессор с частотой от 1,6 ГГц
- 2 Гб оперативной памяти
- Две видеокарты на базе G92 (GeForce 9800/Quadro FX) или более нового графического процессора для локальной отладки, одна для удалённой.
- Microsoft Visual Studio 2008 SP1 или новее
- NET Framework 3.5
- Инструментальный драйвер версии 260.93: для Windows 32-bit (~100 Мб), для Windows 64-bit (~140 Мб).
Для получения одной бесплатной лицензии на стандартную версию пакета требуется регистрация на специальном сайте. Расширенная лицензия (с дополнительными функциями, такими как визуальный анализатор производительности и удалённая отладка) стоит USD 349 на год.

Также NVIDIA обновила документацию для разработчиков игр по обеспечению совместимости с системами стереовидения NVIDIA 3D Vision (PDF, ~1 Мб) и 3D Vision Surround (PDF, ~2 Мб). Будем надеяться, что игроделы будут ей следовать, и мы увидим в будущем больше игр с корректно работающим стереорежимом.
CUDA Toolkit 3.2
Предварительная версия для разработчиков.
NVIDIA анонсировала следующую версию средств для разработки CUDA Toolkit для API CUDA. В новой версии 3.2, как сообщается, разработчиков ожидают следующие новшества:
- Новые библиотеки CUSPARSE (для операций с матрицами) и CURAND (генератор случайных чисел).
- Улучшение производительности библиотек CUFFT и CUBLAS на архитектуре Fermi.
- В состав CUDA Toolkit теперь включены библиотеки для работы с видео в формате H.264.
- Добавлена поддержка новых продуктов Quadro и Tesla с объёмом буфера более 4 Гб, включая отладку на таких конфигурациях.
- Отладка многопроцессорных конфигураций в cuda-gdb и Parallel Nsight.
- Поддержка Fermi в cuda-memcheck.
- Поддержка компилятора Intel C в 64-битных версиях Linux в NVCC.
- Поддержка функций malloc() и free() в ядре CUDA-программы.
- nvidia-smi поддерживает выдачу нескольких новых счётчиков производительности, включая загрузку GPU.

Доступ к предварительной версии CUDA Toolkit 3.2 осуществляется через бесплатную регистрацию на сайте NVIDIA для разработчиков.
NVIDIA выпустила новый CUDA Toolkit 3.1
Разработчики, использующие мощности GPU для ускорения приложений, могут скачать и использовать новую версию CUDA Toolkit, которая доступна для Windows, Mac OS и Linux.

Пакет CUDA Toolkit 3.1 включает следующие изменения и дополнения:
- GPUDirect позволяет другим устройствам прямой доступ к памяти CUDA;
- поддержка параллелизма в 16 потоков позволяет использовать одновременно до 16 различных ядер на графических процессорах архитектуры Fermi;
- runtime-драйвер совместимости приложений позволяет универсально использовать драйверы CUDA API с CUDA C Runtime и математическими библиотеками с помощью буфера обмена и миграции;
- добавлены новые возможности языка CUDA C/C++:
- поддержка printf() в коде устройства;
- поддержка функций указателя и рекурсии облегчит портирование многих существующих алгоритмов для Fermi GPU;
- Unified Visual Profiler теперь поддерживает CUDA C/C++ и OpenCL, а так же включает поддержку трассировки CUDA драйверов API;
- математические библиотеки увеличили производительность, в часности:
- улучшенна производительность отдельных трансцендентных функций log, pow, erf, и gamma;
- значительно улучшена производительность для двойной точность FFT при исполнении на архитектуре графических процессоров Fermi для 2^N преобразований;
- потоковый API теперь поддерживается в CUBLAS для перекрытия операций копирования и вычисления;
- оптимизированы CUFFT Real-to-complex (R2C) и complex-to-real (C2R) для 2^N размеров данных;
- улучшена производительность для GEMV и SYMV подпрограмм в CUBLAS;
- оптимизирована реализация вычислений с двойной точностью по принципу разделения и взаимного использования программ для архитектуры Fermi;
- новые и обновленные примеры SDK кода демонстрирует использование:
- функции указателей в ядрах CUDA C/C++;
- буфера обмена OpenCL/Direct3D;
- Hidden Markov Model в OpenCL;
- пример Microsoft Excel GPGPU, показывающий как запускать функции Excel на GPU.

Скачать новую версию CUDA Toolkit вы можете на официальной странице.
AMD предлагает инвестировать средства на поддержку разработчиков программ для архитектуры Fusion
AMD имеет большие планы на Fusion и планирует выделять инвестиции, направленные на создание прочной базы разработчиков.
В интервью PC World, директор AMD по продажам Fusion Джон Тейлор объявил о планах AMD по инвестированию в программное обеспечение для разработки приложений, предназначенных для нового поколения процессоров. Тейлор также отметил, что AMD будет вкладывать средства в компании, занимающиеся разработкой оборудования и комплектующих для поддержки архитектуры Fusion.
Тейлор отметил, что целью AMD является ускорение внедрения уникальных решений и вычислительных приложений, специально разработанных для использования комплексной архитектуроы Fusion. Он отметил, что графические процессоры могут, среди прочего, ускорять приложения рендеринга и обеспечивать безопасность браузеров.
Ранее AMD и NVIDIA поддержали усилия по использованию GPU при вычислениях. AMD оказывает помощь разработчикам OpenCL, а NVIDIA оказывает содействие развитию CUDA в течение многих лет.

Тейлор подтвердил, что AMD уже сделала некоторые, связанные с Fusion, стратегические инвестиции, но не раскрыл название компаний, принимающих участие в программе.
Подробнее вы можете прочитать на сайте pcworld.com (на английском).
Intel утверждает, что современные видеокарты NVIDIA всего лишь в 14 раз быстрее Core i7-960
Компания Intel на основе внутренних тестов сделала заявление, что её топовые процессоры всего лишь в 14 раз медленнее, чем видеокарты компании NVIDIA . Цель этого - опровергнуть заявления NVIDIA, что её графические процессоры превосходят процессоры Intel до 100 раз.
В документе под названием "Debunking the 100x GPU vs CPU Myth" Intel предполагает, что в некоторых случаях NVIDIA GeForce GTX 280 до 14 раз быстрее, чем Intel Core i7-960. Intel утверждает, что в среднем величина преимущества составляет 2,5 раза. Естественно, что NVIDIA тут же опубликовала опровержение этого.
В блоге, пресс-секретарь Andy Keane отметил, что Intel использовала не последнее поколение GPU от NVIDIA, правильнее было сравнивать с видеокартами семейства Fermi. Keane также отмечает, что Intel скорее всего запускала не оптимизированный код на GTX 280, и не понятно, как они сопоставили производительность GPU и центрального процессора.

Cотрудник NVIDIA признал, что не все приложения работают в 100 раз быстрее на GPU, но он привел в пример многих разработчиков, которые добились этого. По крайней мере, семь разработчиков заявили о преимуществе свыше 100 раз, и один заявил о цифре 300 раз.
![]()
Новые программы аттестации и сертификации NVIDIA для CUDA/GPGPU
На этой неделе, на конференции ISC 2010 в городе Гамбурге, Германия, NVIDIA объявила о новых программах для всё более растущего сообщества разработчиков CUDA/GPGPU.
- CUDA Certification Program. Программа сертификации CUDA разработана в связи с нехваткой квалифицированных инженеров, это первая программа массовой сертификации специалистов, занимающихся параллельным программированием на графических процессорах.
- CUDA Research Centers. Исследовательские центры CUDA будут проводить аттестацию учреждений, занимающихся вычислениями на GPU в различных областях научных исследований.
- CUDA Teaching Centers. Обучающие центры CUDA будут охватывать научные учреждения, которые внедрили вычислительные технологии на базе GPU в свою основную программу занятий.

Эти программы дополняют существующую программу CUDA Center of Excellence, которая охватывает на сегодняшний момент 10 научных учреждений во всем мире.
Детали новости можно посмотреть на официальном сайте.
Релиз CUDA Toolkit 3.0
К выходу Fermi — новая версия инструментов CUDA для разработчиков.
В CUDA 3.0 сделаны значительные изменения:
- поддержка новой архитектуры Fermi;
- поддержка классов C++;
- взаимодействие CUDA и OpenCL с Direct3D 9/10/11 и OpenGL;
- возможность использования в одном приложении и CUDA Runtime, и CUDA Driver API.
- многократное повышение производительности при отладке в cuda-dbg и аппаратное ускорение отладки для CUDA Driver API на видеокартах с архитектурой Fermi;
- утилита CUDA Memory Checker для поиска ошибок выравнивания данных и переполнения памяти;
- ряд важных улучшений в OpenCL.

Загрузить CUDA SDK, документацию и отладочные драйверы для Windows, Linux и MacOS можно со специальной страницы сайта NVIDIA для разработчиков.
NVIDIA ускоряет работу движка Adobe Mercury Playback
Как мы уже сообщали, новая версия профессиональной программы для монтажа и обработки видео, Premiere Pro от компании Adobe, будет оснащена переработанным движком Mercury Playback Engine.
Этот движок с помощью видеокарт NVIDIA позволяет значительно ускорить скорость рендеринга сцен с наложением множества слоёв, с добавлением эффектов и проч. Также благодаря CUDA и видеокартам NVIDIA Quadro ускоряется и предварительный просмотр результатов монтажа.
Всё это стало возможным благодаря тесной работе разработчиков из Adobe с командой специалистов из NVIDIA во главе с Андрю Креши, который рассказал немного о работе своей команды в небольшом видеоролике.

Интервью с Дэвидом Кирком о его книге
Доктор Дэвид Кирк, главный учёный NVIDIA, относительно недавно в соавторстве с доктором Вен-мей Хву написал книгу «Programming Massively Parallel Processors: A Hands-on Approach».
Книга посвящена основам и методам программированию на языке CUDA. На специальном видеоролике, выложенном NVIDIA в своём блоге, господин Кирк немного рассказывает о своей книге. Он говорит, что она создана для начинающих программистов, студентов и профессионалов, желающих понять архитектуру и основные принципы работы GPU.
Также он отмечает, что уже сейчас CUDA преподаётся в 300 университетах и наличие такого пособия является очень важным для преподавания. Также он сказал, что думает о будущих изданиях книги, в которых будут раскрыты особенности программирования с использованием возможностей будущих высокопараллельных графических процессоров.
Подробнее узнать о книге можно на специальном мини-сайте. Купить книгу можно в интернет-магазинах: Elsevier, Amazon или Barnes & Noble.

NVIDIA любит все API, поддерживающие GPU-вычисления
Как известно, Microsoft продвигает DirectCompute для Windows 7, а Apple — OpenCL в Snow Leopard, но NVIDIA верит, что обе компании вдохновлены CUDA.
Иен-Сан Юань во время своего последнего визита в Китай сказал: «Нам нравятся оба эти API, и мы первыми представили компиляторы и драйверы для них. Мы выпустили первый OpenCL-драйвер, первый драйвер с DirectCompute, при этом у нас до сих пор лучший в мире OpenCL-драйвер и мы всё ещё имеем лучший DirectCompute-драйвер, а также лучший в мире CUDA C-компилятор. Причина, по которой мы любим эти API в том, что нам нравятся любые методы программирования GPU».

Он также заметил, что как DirectCompute, так и OpenCL преимущественно сфокусированы лишь на одной операционной системе, тогда как CUDA является куда более открытой платформой.
Также господин Юань подчеркнул преимущества CUDA в качестве стандарта: «Если вам нужны GPU-вычисления для Linux, у нас есть CUDA, если вам нужны GPU-вычисления в будущем для Android, CUDA на сотовых телефонах, или GPU-вычисления на сотовых телефонах, у нас есть CUDA».
15 октября NVIDIA выпустит бета-версию Nexus
На технологической конференции, посвященной видеоускорителям, (GPU Technology Conference), которая проходит сейчас в Сан-Хосе, NVIDIA снова показала свою разработку Nexus — первую среду GPU/CPU-разработки, интегрированную в Microsoft Visual Studio.
Nexus поддерживает Windows 7 и Vista и дает возможность разработчикам приложений, использующим вычислительные мощности видеокарт, с помощью средств Microsoft Visual Studio не прибегать к необходимости создавать различные версии программ.
Пакет Nexus включает:
- Отладчик кода CUDA C, HLSL и DirectCompute, поддерживающий контрольные точки источника и данных, а также прямой анализ использования памяти видеокарты. Вся отладка исполняется непосредственно на оборудовании.
- Инструмент для оценки производительности системы с учетом GPU-событий (ядра, запросы API, передачи по памяти) и CPU-запросов (использования ядер, события передачи запросов и их обработки, а также интервалов ожидания) — всё это отражается на единой взаимосвязанной временной шкале.
- Графический инспектор предоставляет разработчикам возможность отладки и профилирования кадров, визуализированы с помощью таких API, как Direct3D. Разработчики смогут использовать этот инструмент для изучения влияния каждой текстуры, вершинных буферов и состояния API в кадре.

NVIDIA планирует выпустить бета-версию Nexus 15 октября. Более подробно с этой средой разработки можно ознакомиться на официальном сайте NVIDIA для разработчиков. Там можно увидеть Nexus в работе, узнать возможности, которые будут включены в бета-версию, а также изучить новую архитектуру CUDA в связи переходом в Fermi на принцип MIMD (Many Instructions Many Data).
NVIDIA: DirectX 11 не увеличит продажи графических карт
На прошедшей конференции с финансовыми аналитиками NVIDIA усиленно убеждала своих партнеров, инвесторов и общественность в том, что новый API DirectX 11, в общем-то, не способен поднять продажи графических карт. А будущее за GPGPU-технологиями вроде DirectX Compute, которая уже поддерживается современными видеоускорителями. Однако, как известно, часто не технологии поднимаю продажи, а маркетинговый отдел.

Майк Хард, вице-президент NVIDIA по связям с инвесторами, на технологической конференции, прошедшей в среду в Deutsche Bank Securities, объяснял партнерам компании, что Microsoft стремится дать разработчикам больше свободы для творчества и новые возможности в DirectX 11, действительно, достигают этой цели, но новый API — не единственная причина, которая способна побудить пользователей к приобретению нового ускорителя.
Он также сделал акцент на том, что пользователи не только играют, но и работают с домашним видео и фотографиями. CUDA уже можно причислить к списку факторов, влияющих на выбор покупателей. Но, думается, дело тут не в реальной полезности технологии, которую пока рядовой пользователь вряд ли может рассматривать серьезно. Маркетологи NVIDIA закрывают глаза на то, что до сих пор на рынке представлены единицы программ, способных задействовать мощности видеокарты. При этом данные программы (Badaboom, MediaShow, LoiLoScope) стоят немалые деньги и могут предоставить лишь ограниченную функциональность, которая не способна удовлетворить нужды большинства людей. Число успешных игр, в которых реализована расширенная поддержка физических эффектов, также невелико, среди них: Batman Arkham Asylum и Mirror’s Age. Одновременно очень богатыми физическими эффектами обладает Red Faction Guerilla, где все расчеты осуществляются процессором.
![]()
Нет сомнения, что DirectX 11 — пока тоже остается инструментом маркетинга, ведь большинство современных игр еще очень слабо используют возможности даже DX10, а широкое внедрение новых функций DX11 можно не ждать в ближайшие год—два. Тем более, что игры, написанные на DX11 будут работать быстрее и на современных DX10-видеокартах благодаря внесенным оптимизациям в работу с многоядерными процессорами.
Видеокарты нового поколения от AMD уже через месяц поступят в широкую розничную продажу, что касается NVIDIA, то даже её планы остаются в густом информационном тумане. Безусловно, будь NVIDIA первой, покупателям пришлось бы услышать массу благожелательных слов о DX11 и его очевидной пользе, однако, NVIDIA в настоящее время находится в числе отстающих в технологической гонке и вынуждена призывать потребителей к здравомыслию в отношении новых технологий. Мы тоже присоединяемся к словам маркетологов NVIDIA: сейчас в DirectX 11 практического смысла нет.
NVIDIA предсказывает быстрый рост производительности
Глава NVIDIA, Иен-Сан Юань, предсказал, что развитие вычислений общего назначения средствами видеокарт позволит быстро наращивать производительность в ближайшие годы.
Так, по его мнению, GPU-вычисления за шесть ближайших лет позволят увеличить вычислительные способности ПК в сравнении с настоящими в 570 раз, тогда как развитие центральных процессоров за то же время позволит увеличить производительность лишь в 3 раза. Такое сильное увеличение производительности видеокарт в расчетах общего назначения открывает перспективы перехода на визуализацию методом трассировки лучей.

Действительно, высокопараллельные расчеты крайне неэффективно исполняются на современных центральных процессорах. Графические карты, напротив, справляются с такими задачами отлично. С распространением таких языков как CUDA, OpenCL и DirectX Compute, множество вычислительных задач будет значительно ускорено.
Слайды NVIDIA, посвященные Windows 7 и DirectX Compute
В своей внутренней презентации, проведенной для основных клиентов, NVIDIA продемонстрировала несколько интересных слайдов, посвященных технологии DirectX Compute и ОС Windows 7.
На первом слайде отмечается, что благодаря технологии DX Compute некоторые задачи могут быть ускорены в 5—20 раз в сравнении с вычислениями средствами только центрального процессора. Технология поддерживается видеокартами серий GeForce 8, 9, 200 и будущими DX11-решениями.

Второй слайд посвящен приложениям, которые уже реально ускоряют, благодаря мощности видеокарт NVIDIA, задачи декодирования видео, наложение эффектов, кодирование видеопотока, улучшения видео и его редактирование. Среди них есть Cyberlink PowerDirector, MotionDSP vReveal и, конечно, Badaboom.

Третий слайд отмечает, что Windows 7 работает через два процессора: центральный и графический (с поддержкой DirectX Compute).

Четвертый слайд сообщает, что благодаря использованию видеокарты Windows 7 намного лучше справляется с мультимедийными задачами, задачами управления ПК и с игровыми приложениями с PhysX.

Последний слайд сообщает о том, что Windows 7 на 10 % более эффективно использует мощь многочиповых графических конфигураций SLI в сравнении с Windows XP.

NVIDIA готовит A100 с жидкостным охлаждением
В Сети появилась фотография нового варианта ускорителя A100 Tensor Core от NVIDIA, который имеет водяную систему охлаждения.
Ускоритель A100 основан на GPU GA100 Ampere. Он является предшественником ускорителя для ЦОД модели H100 Hopper. Таким образом, речь идёт о новом варианте с жидкостным охлаждением модели A100 PCIe, выпущенной год назад. Это не вариант SXM, используемый для систем HGX/DGX A100.

Стоит отметить, что жидкостное охлаждение в серверах не принято, и сейчас мы наблюдаем от NVIDIA экстраординарный шаг. Зато данное решение обладает тонкой конструкцией со штуцерами для подключения охлаждения, расположенными на задней стенке.


Стоит отметить, что жидкостное охлаждение для ускорителей A100 уже широко применяется, однако для этого требуется ручная замена массивного воздушного охлаждения. Пассивное воздушное охлаждение часто оказывается неэффективным, а потому NVIDIA и решила применять водяное охлаждения.
NVIDIA скоро изготовит мультичиповый GPU Hopper
В Сети появились слухи, что в скором времени NVIDIA изготовит новый GPU под именем Hopper. Тут важно отметить, что это не игровое решение, и вы не увидите карту GeForce RTX 4080 Ti на его основе. Тем не менее, это инновационное решение.
В Twitter, в аккаунте Greymon55, появилось шифрованное сообщение с аббревиатурой «NHWTOS», которая через пару часов была расшифрована. Она гласит «NVIDIA's Hopper Will Tape Out Soon», то есть «NVIDIA Hopper скоро будет отпечатан».
Эта новая архитектура примечательна тем, что в ней используется мультичиповый модуль, вместо традиционного монолитного. И хотя этот процессор предназначен для суперкомпьютеров, нам он интересен по причине того, что его опыт может быть применён на поколении Lovelace или даже обновлённой версии Ampere, который планируются в 2024 и 2022 годах соответственно.

Мультичиповая технология в Hopper аналогична той, что использует AMD в своих центральных процессорах Zen и графических процессорах RDNA. Она изготавливает свои процессоры на TSMC, и новый чип NVIDIA также должен быть изготовлен на TSMC по 5 нм нормам. Ожидается, что чиплет из двух ядер GPU предложит в сумме 288 потоковых мультипроцессоров, что в 2,6 раза больше, чем у GPU NVIDIA A100. Кроме того, Hopper будет более энергоэффективным, чем Ampere. Считается, что его энергетическая эффективность вырастет в 3 раза.
Как обычно, к подобным слухам следует относиться с большой осторожностью и скептицизмом. Тем более, что они получены из неизвестных источников.
NVIDIA отказывается от бренда Tesla
Компания NVIDIA использовала бренд Tesla для своих продуктов GPGPU начиная с 2007 года.
На прошлой неделе, когда фирма представила графический процессор для ЦОД с кодовым именем Ampere, она назвала его A100. Никакой отсылки к «Tesla». Это слово просто исчезло из официальных сообщений компании.

Немецкий сайт Heise сообщает, что крупнейший производитель дискретных видеоускорителей решил отказаться от бренда Tesla, чтобы избежать возможных недоразумений и путаницы с одноимённой компанией-производителем электрокаров Илона Маска. Сообщается, что NVIDIA провела изменения в прошлом году, когда осуществила ребрендинг ускорителей на основе GPU Turing, заменив «Tesla T4» на «NVIDIA T4».
О возможных юридических проблемах ничего не сообщается. Кроме того известно, что компании активно сотрудничали друг с другом по обеспечению автопилота на электрокарах Tesla.
Энтузиасты создают открытый аналог CUDA
Разработчик GitHub с ником jgbit открыл проект с открытым исходным кодом, который назвал VUDA.
Идея этого проекта заключается в реализации аналога API NVIDIA CUDA, простого интерфейса для GPU вычислений, в мире свободного ПО.

Система VUDA работает поверх уже набравшего популярность графического API Vulkan, который обеспечивает доступ к аппаратному обеспечению на низком уровне. VUDA является библиотекой C++, что означает совместимость со всеми платформами, которые имеют компилятор C++ и поддерживают Vulkan.

Пока проект находится на начальном этапе, но его потенциал трудно представить, особенно, учитывая открытую лицензию. На GitHub приведен простой пример использования библиотеки, который может стать хорошим началом для будущих разработок.
NVIDIA представила профессиональную карту на базе Turing
Сегодня компания NVIDIA представила первую видеокарту новой архитектуры Turing. Её процессор оснащён специальными ядрами «RT Core» для трассировки лучей, сложной техники, дающей предельно фотореалистичную картинку. Благодаря им эти расчёты теперь могут выполняться в реальном времени.
В компании отметили, что представленная видеокарта Quadro RTX стала «первым GPU для трассировки лучей» и одновременно является крупнейшим прорывом для компании с 2006 года, когда была представлена технология CUDA.

Даже по названию очевидно, что это будет карта для профессиональной работы. Ускоритель Quadro RTX 8000 будет стоить 10 000 долларов, когда он будет доступен к концу года. Плата будет содержать целых 48 ГБ видеопамяти GDDR6. Её графический процессор получит 4608 ядер CUDA и 576 тензорных ядер. Скорость трассировки лучей названа NVIDIA на уровне 10 гигамассивов в секунду, а общая производительность составит 16 терафлопс. Графический процессор получит интерфейс NVLink, а значит NVIDIA предполагает масштабирование видеокарт. Также из интерфейсов стоит отметить наличие порта VirtualLink, предназначенного для будущих устройств виртуальной реальности.
Анонс видеокарты состоялся в ходе SIGGRAPH, конференции для профессионалов в области компьютерной графики. На следующей неделе ожидается анонс игровых видеокарт на базе GPU Turing. Что это будут за ускорители, по-прежнему остаётся загадкой.
NVIDIA выпускает CUDA 9
Компания NVIDIA отметила новый этап в индустрии HPC и AI, анонсировав финальную спецификацию CUDA 9.
Предрелизная спецификация CUDA 9 была выпущена достаточно давно, но только теперь появилась финальная версия.

Кроме поддержки новой архитектуры и оптимизации библиотек, совсем скоро появятся совершенно новые приложения. Главные изменения в CUDA 9 включают:
- Ускорение высокопроизводительный вычислений (HPC) и в приложениях глубокого анализа с новыми ядрами GEMM в cuBLAS.
- Более быстрое исполнение приложений обработки изображений и сигналов на нескольких GPU в cuFFT и NVIDIA Performance Primitives.
- Решение линейных и графических аналитических проблем, общих для HPC, с новыми алгоритмами в cuSOLVER и nvGRAPH.
- Ускоренные распараллеленные алгоритмы с потоками из подэлементов в кривых, блоках и сетках.
- Управление и эффективное повторное использование потоков внутри приложений с новым API и функциональными примитивами.
- Оптимизация и предварительная подготовка доступа к памяти по идентификации исходного кода, приводящего к ошибкам на странице унифицированной памяти.
- Унифицирована производительность в узких местах памяти с новыми фильтрами, основанными на виртуальных адресах, причинах миграции и типах ошибок адресации страниц.
Также компания добавила ряд изменений для поддержки архитектуры Volta и технологии NVLink.
Otoy реверсно разработал NVIDIA CUDA для не-NVIDIA устройств
Разработчик Otoy анонсировал программное обеспечение OctaneRender, которое позволяет запускать NVIDIA CUDA приложения на аппаратном обеспечении отличном от NVIDIA.
Компания отмечает, что CUDA является превосходной альтернативой OpenCL и позволяет создавать намного более богатое графическое ПО. Именно поэтому Otoy и решила разработать CUDA методом реверс инжиниринга, и создала единый CUDA код, который можно запускать на GPU не только от NVIDIA, но и разработки AMD, ARM и Intel.

Основной целью разработки является предоставление CUDA приложений, таких как Octane, для Apple Metal GPGPU API под OSX и iOS, где заметно не хватает OpenCL 2.1, Vulkan и OpenGL ES.
Разработчики отметили, что они мечтали сделать превосходные CUDA программы доступными для разработчиков игр на таких устройствах как компьютеры Mac и iOS. В Otoy адаптировали Octane для работы в качестве плагина для игрового движка, как движок Epic Unreal.
Новая функция появится вместе с релизом Otoy Octane 3.1. Подробную информацию можно найти на сайте VentureBeat.
Обновилась популярная информационная утилита GPU-Z до версии 0.8.7
Сайт TechPowerUp подготовил очередное обновление своей популярной утилиты GPU-Z, предназначенной для получения всей доступной информации о вашей видеокарте и мониторинга её параметров. Обновление получило номер 0.8.7.
Версия 0.8.7 утилиты в основном характеризуется различными исправлениями ранних ошибок, в числе которых неверное определение устройств, устранение зависаний, детекция поддержки различных технологий и их версии. Также база данных видеокарты расширилась целым рядом графических ускорителей NVIDIA, AMD и Intel.

Полный перечень изменений приведён ниже:
- Теперь правильно определяется версия драйвера Radeon Software Crimson Edition.
- Исправлено чтение напряжения GPU 1,55 В на процессорах AMD Fiji.
- Исправлен на верный 12_1 уровень возможностей DirectX на iGPU Skylake.
- Исправлен синий экран на Intel Cloverview (Atom Z2760).
- Исправлено определение CUDA для устройств с номером шины большем 9.
- Исправлено наименование AMD Beema.
- Улучшено объяснение определения ошибок OpenCL на GPU AMD.
- Некоторые карты HD 2000 и HD 3000 теперь корректно определяются как ATI.
- Версия ID теперь всегда отображается двумя цифрами.
- Исправлено отображение шейдерной модели на старых картах.
- Исправлена миллисекундная точность во временных отметках файла журнала.
- Обновлён перевод американского английского.
- Прочие исправления стабильности.
- Добавлена поддержка NVIDIA GTX 980M 8GB, GTX 965M, GTX 750 (GM206), GT 710 (GK208), Quadro K1200, M5000, M2000M, M1000M, K2200M, GRID K160Q, Tesla K80.
- Добавлена поддержка AMD R9 380X, R7 350, Mullins.
- Добавлена поддержка Intel Skylake Graphics 510, P530, 540.
Загрузить бесплатную утилиту GPU-Z можно с нашего сайта.
NVIDIA предсказывает общедоступность суперкомпьютеров
В ходе недавней конференции в Остине, штат Техас, исполнительный директор NVIDIA Дзень-Хсунь Хуан рассказал, что видит широкие возможности для распространения суперкомпьютеров во многих отраслях промышленности.
Хуан пояснил, что суперкомпьютерные технологии хорошо продвигаются за пределы традиционных суперкомпьютерных систем, и технологии GPU станут частью будущих технологий, таких как автономные транспортные средства и персональные роботизированные помощники. Компания NVIDIA уже активно работает в этих отраслях, предложив автомобильный компьютер NVIDIA Drive PX и модуль машинного обучения Jetson TX1.

За последние пару лет графические процессоры нашли своё применение во многих суперкомпьютерах. По словам NVIDIA, использование GPU акселераторов в списке top500 суперкомпьютеров растёт ежегодно на 50%, а графический процессор Tesla использован в 23 из 24 новых суперкомпьютерах с GPGPU ускорением.
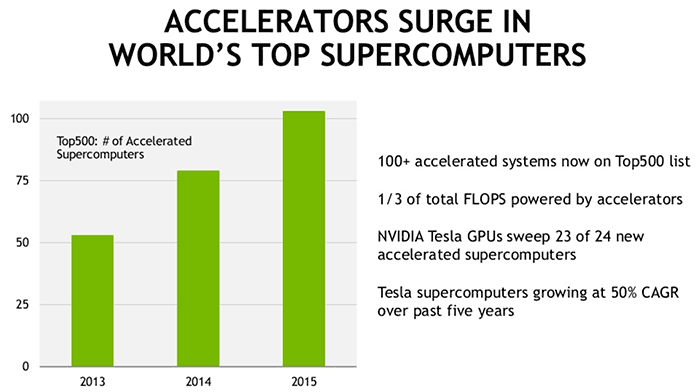
В будущем машинное обучение увеличит спрос на GPU ещё больше. Машинное обучение является «первоочередным применением высокопроизводительных вычислений для потребителей» — отметил Хуан. «Технология позволит технологии стать автономной в сложности реального мира и станет инструментом для производства автономных транспортных средств и машин, подобных персональным роботам-помощникам».