NVIDIA дала ряд комментариев по внутреннему устройству Fermi
Сайт PCGamesHardware.com задал NVIDIA вопросы по работе архитектуры GF100 и получил некоторые ответы.
Мы приводим некоторые выяснившиеся факты об архитектуре Fermi:
- Чип GF100 содержит ровно 3 миллиарда транзисторов.
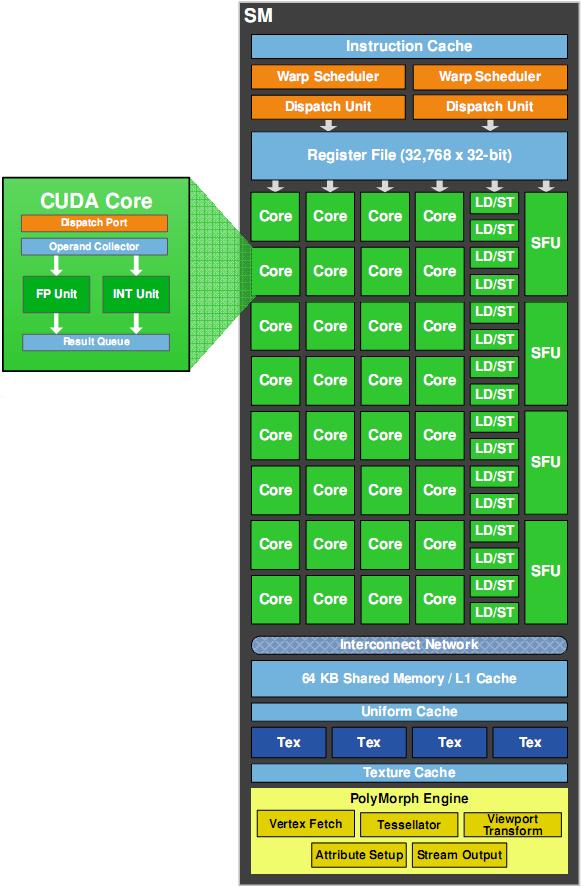
- На частоте hot-clock (1401 МГц для GeForce GTX 480 и 1215 МГц для GTX 470) работают только шейдерные ядра. Все остальные блоки, не считая контроллеров памяти, работают на частоте ядра (700/607 МГц).
- Блоки Load/Store в GPC не используются для загрузки текстур. Их последовательность работы с памятью выглядит как L1→L2→VRAM, в то время как блоки загрузки текстур работают как кэш текстур→L2→VRAM.
- В GF100 действительно доступно меньше регистров для одного CUDA-ядра, чем было в GT200. Но в NVIDIA по итогам внутреннего тестирования не обнаружили проблем из-за этого, кроме того, специально для вычислений с большой рабочей областью введен кэш L1.
- Блок INT в CUDA-ядре не простаивает в графических задачах, в частности, он используется для часто встречающихся операций сравнения.
- Кэш GPU поддерживает управление механизмом кэширования, клиент может запрашивать ту или иную стратегию кэширования для каждого запроса индивидуально.
- В продуктах семейства GeForce на базе GF100 вычисления с двойной точностью действительно выполняются не с теоретической производительностью ½ от быстродействия вычислений с одинарной точностью, а лишь с ⅛. Полная скорость таких вычислений доступна лишь в продуктах Tesla.
- Реальное быстродействие GT200 в установке геометрии составляло лишь 0,5 треугольников на такт частоты ядра, большая производительность получалась лишь с учётом отбрасывания невидимых объектов. Поэтому полная теоретическая производительность GF100 в 4 треугольника/секунду действительно в 8 раз больше.
- Хотя само ядро GF100 способно выдавать лишь 32 пиксела/такт (с учётом отключенных блоков SM — 30 для GTX 480 и 28 для GTX 470), конфигурация блоков ROP (48/40) рассчитана не на число пикселов на выходе с GPC/SM, а на число выборок после работы алгоритмов FSAA, для повышения производительности полноэкранного сглаживания.