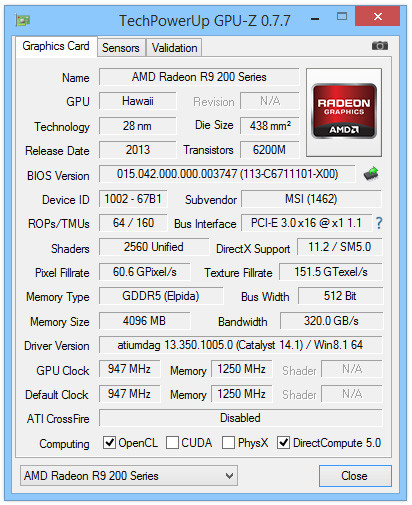
До версии 0.7.8 обновилась популярная утилита, предназначенная для получения всей доступной информации о вашей видеокарте и мониторинга её параметров.
В новой версии программы был изменён пользовательский интерфейс, предложив возможности изменять размер окна приложения при просмотре закладки с датчиками. Учитывая то, что современные видеокарты предлагают десятки параметров для контроля, было решено применять полосу прокрутки для отображения показаний датчиков с возможностью изменения размера окна. Правда, пока эти изменения работают на обычной версии GPU-Z без применения скинов.
Полный список изменений включает:
Можно менять размер окна GPU-Z при активной вкладке датчиков.
Исправлено некорректное чтение для карт GeForce Tesla.
Добавлена поддержка AMD Radeon R9 295X2, R9 M275, HD 7500G, FirePro W9000.
До версии 0.7.6 обновилась популярная утилита, предназначенная для получения всей доступной информации о вашей видеокарте и мониторинга её параметров.
Новая версия программы имеет несколько новых полезных функций, добавлены новые GPU и справлены выявленные ошибки и неточности. В частности, была добавлена графическая архитектура NVIDIA Maxwell, уточнена информация о GPU в готовящихся к выпуску видеокартах GTX 750 b 750 Ti, уточнена работа датчиков для различных видеокарт.
Полный список изменений включает:
Скорость обновления датчиков теперь настраиваема.
Исправлен счётчик TMU и шейдеров в GM107.
Улучшена поддержка NVIDIA Maxwell.
Добавлен мониторинг напряжений CHiL8214 для видеокарт AMD на базе Pitcairn/Curacao.
Словацкая утилита HWiNFO32/64 — это одна из старейших и мощнейших утилит по получению информации о системе, её диагностирования и мониторинга в реальном режиме времени.
Программа позволяют получать сведения о системе, а диагностическая часть поддерживает самые свежие компоненты, промышленные технологии и стандарты. Эти инструменты нацелены на распознавание и извлечение всей возможной информации об аппаратном обеспечении компьютера, что делает утилиты подходящими для пользователей, ищущих драйвера, производителей компьютеров, системных интеграторов и технических экспертов.
В новой версии основное усилие разработчиков было направлено на исправление показаний датчиков материнских плат. Также была расширена база данных программы, в которой появились и уточнились сведения об интегрированных GPU и платах GPGPU.
Полный перечень изменений приведен ниже:
Исправлен отчёт с предупреждением о диске на некоторых SSD.
Добавлены NVIDIA Tesla K40m, K40st, K40s.
Улучшен мониторинг датчиков на материнских платах MSI серии 8.
Исправлен датчик на CPU Intel Haswell-U/Y.
Улучшено распознавание CHiL CHL8318/CHL8266 на GPU.
Улучшен мониторинг датчиков на MSI NF750-G55.
Исправлено сообщения о показаниях датчиков на GPU AMD после отключения питания.
Исправлена нумерация поздних AMD DGPU.
Исправлен мониторинг датчиков на ASUS MAXIMUS VI.
Добавлен мониторинг TSOD на SNB/IVB/HSW/BDW-E/EN/EP/EX.
Исправлен выбор размера шрифта для LG LCD.
Исправлены сообщения о частотах GPU на Haswell GT1.5.
Добавлена поддержка ITE IT8620E HW monitor.
Улучшен мониторинг датчиков на GIGABYTE серии A88X.
Нужной вам разрядности (32 или 64 бита) утилиту можно загрузить с официального ресурса. Как и раньше, программа HWiNFO32/64 беспроблемно работает на всех версиях ОС Windows от XP до 8.1, и, как и прежде, она совершенно бесплатна.
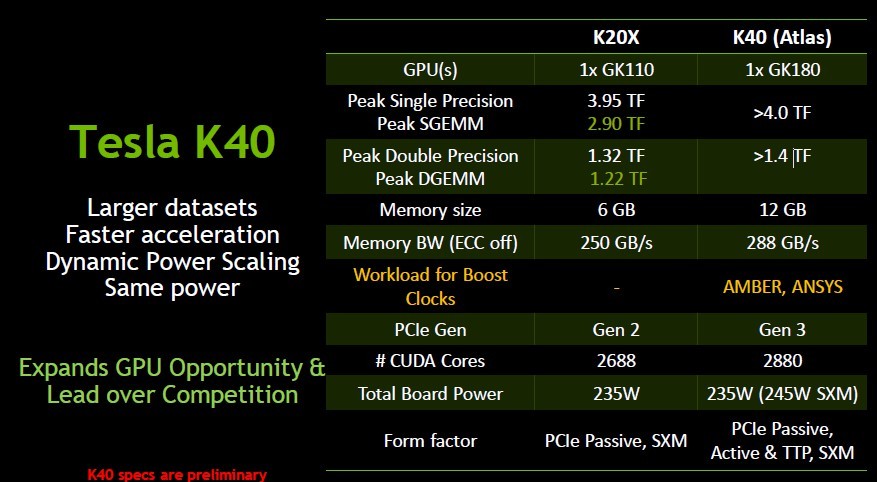
В ходе конференции SC13 компания NVIDIA представила самый производительный в мире видеоускоритель Tesla K40, сделав это вслед за AMD Firepro S10000 12 GB.
Как и положено ускорителям Tesla, он предназначен для суперкомпьютеров и он на целых 40% превышает по производительности Tesla K20X. Кроме того, этот ускоритель в 10 раз быстрее самого быстрого на сегодня CPU. Таким образом, ускоритель Firepro S10000 12 GB пробыл на вершине всего несколько дней.
«GPU ускорители стали мейнстрим продуктом в высокопроизводительных ПК и суперкомпьютерах, позволяя инженерам и учёным создавать новшества и делать научные открытия», — заявил Сумит Гупта, главный менеджер NVIDIA по продуктам ускоренных вычислений.
Что касается аппаратной части, то K40 получил 2880 ядер CUDA с базовой частотой 745 МГц и до 875 МГц в режиме Boost, в то время как прошлое поколение, K20X, имело 2688 ядер частотой 732 МГц. В новой плате также используется более быстрая память GDDR5 частотой 3 ГГц, объём которой также как и противоборствующего лагеря составляет 12 ГБ.
В пресс-релизе компания указала, что «ускоритель Tesla K40 обходит остальные ускорители по двум главным показателям вычислительной производительности: 4,29 терафлопса с обычной точностью и 1,43 терафлопса пиковой производительности с двойной точностью». Надо сказать, что это не совсем правда, поскольку AMD удалось сделать свой ускоритель с производительностью в 1,48 терафлопса при двойной точности вычислений.
Несмотря на недавний анонс, у NVIDIA уже есть первый клиент на новые платы. Им стал Техасский современный вычислительный центр в Остине, который планирует запустить новую интерактивную систему удалённой визуализации и анализа данных, под именем Maverick, уже в январе будущего года.
В Сети появились сведения о том, что компания NVIDIA готовит новый однопроцессорный компьютерный ускоритель модели Tesla K40 с кодовым именем Atlas.
Благодаря слайду NVIDIA, утекшему в Сеть и опубликованному китайским ресурсом ByCare, мы теперь можем знать его спецификации. Итак, карта будет основана на GPU GK180. Об этом чипе пока ничего неизвестно, но учитывая имеющийся слайд, он не слишком сильно отличается от GK110.
Процессор имеет 2880 ядер CUDA. Общая производительность ускорителя составит 4 Тфлопса при обычной точности и 1,4 Тфлопса при расчётах с двойной точностью. Также плата получит 12 ГБ памяти GDDR5, что вдвое больше, чем у Tesla K20X. Память будет иметь пропускную способность 288 ГБ/с. Также ускоритель должен иметь функцию динамического разгона, который работает в режимах ANSYS и AMBER. По сравнению с прошлым поколением, новый ускоритель будет работать с шиной PCI-Express 3.
Сообщается, что карта будет продаваться в двух версиях: в виде дополнительной карты и SXM. В зависимости от этого будет меняться и энергопотребление, которое составит 235 Вт или 245 Вт соответственно.
На днях компания NVIDIA подтвердила информацию о том, что она планирует объединить свои GPGPU с 64 битными процессорами ARM в будущих продуктах Tesla.
Согласно информации, появившейся на сайте InfoWorld, главный технолог линейки продуктов Tesla Стив Скотт (Steve Scott) сообщил: «В недалёком будущем Tegra собирается обрести возможности GPU вычислений. Когда-нибудь в этом десятилетии мы также собираемся обеспечить совместную интеграцию CPU и GPU в линейке Tesla».
«Когда-нибудь в этом десятилетии» — это не совсем понятная формулировка, но мы полагаем, что это случится где-то в 2015 году.
Скотт имел ввиду процессоры ARMv8, недавно анонсированные под именами Cortex-A53 и A-57, которые должны поступить в массовое производство в 2014 году. Надо отметить, что NVIDIA не присоединилась к лицензированию ARMv8, хотя в число компаний-лицензентов входит AMD, Broadcom, Calxeda, HiSilicon, Samsung и STMicroelectronics.
В любом случае, выход на развивающийся рынок микросерверов, это реальная возможность для эволюции бизнеса NVIDIA. Объединение Tesla с ядрами ARMv8 позволит компании конкурировать в сегменте рынка, который будет заполнен такими тяжеловесами как Samsung, Qualcomm, Texas Instruments и Intel со стороны x86. Также на этом рынке компании придётся соревноваться со своим старым конкурентом — AMD.
Несмотря на множественные разговоры о разработках компании в промышленности, науке и бизнесе, которые состоялись на NVIDIA GPU Technology Conference, компания не забыла и об игровых графических процессорах.
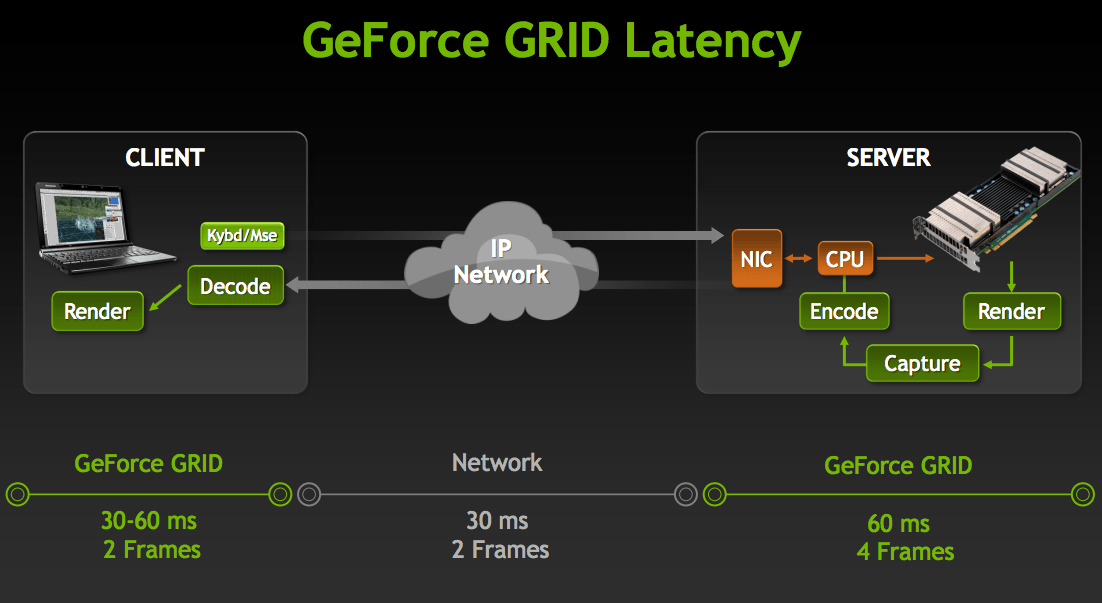
Сегодня NVIDIA анонсировала то, что было названо облачной игровой платформой GeForce Grid, которая представляет собой потоковый сервис виртуализации игр будущего поколения на любом устройстве без заметных задержек, которые могут ухудшить геймплей.
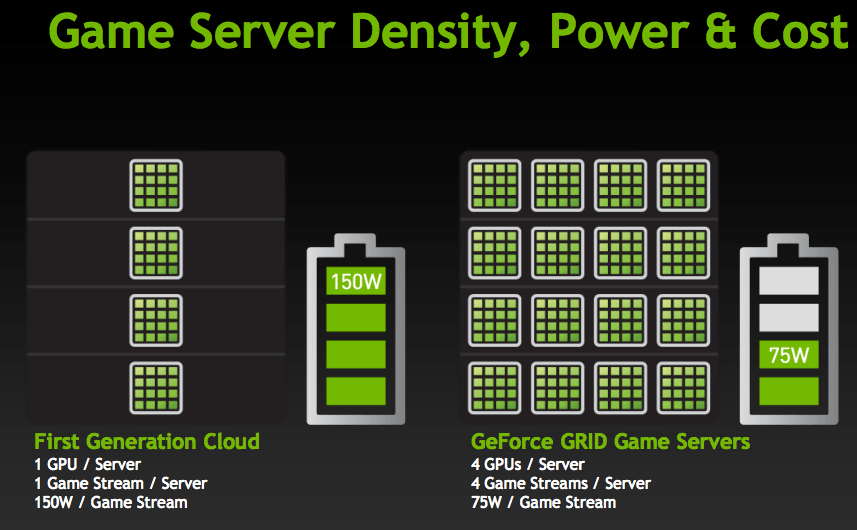
Используя архитектуру Kepler, GeForce Grid GPU минимизирует энергопотребление, позволяя кодировать одновременно до восьми игровых потоков. Это даёт возможность провайдерам повысить экономическую эффективность служб, предлагая одновременно услуги сотням игроков.
В основе предложенного решения лежит двухпроцессорная видеокарта, при этом каждый GPU имеет собственный кодировщик. Суммарно два процессора имеют 3072 ядра CUDA, общая вычислительная способность которых составляет 4,7 терафлопса. Вся эта мощь позволит провайдерам услуги осуществлять рендер высокосложных игр в облаке, кодировать их на GPU, быстрее чем на CPU, что обеспечит большее число одновременно обрабатываемых потоков. Благодаря новой энергоэффективной архитектуре, весь вычислительный центр будет потреблять в два раза меньше электроэнергии, чем на предыдущих видеоускрителях.
На конференции GTC компания NVIDIA, совместно с Gaikai, продемонстрировали виртуальную игровую консоль на телевизоре LG Cinema 3D Smart TV, на котором работало приложение Gaikai, подключенное к серверу с GeForce Grid GPU, расположенном в 10 милях. В результате был показан быстрый и сглаженный геймплей без каких-либо заметных задержек. При этом телевизор был подключен посредством кабеля Ethernet, а игровой контроллер через беспроводной USB адаптер.
На вопрос об уровне задержек исполнительный директор NVIDIA Дзень-Сунь Хуан разъяснил, что задержки их системы составляют порядка 100 мс, что даже немного лучше, чем на современных консолях. Это достигается за счёт того, что нынешние приставки построены на технологиях 7-и летней давности, кроме того, ускоритель Kepler не использует кадровый буфер ввиду высокой производительности.
В будущем NVIDIA видит возрастающую популярность сервисов вещания игр, подобных Netflix. По мнению компании, видеопроцессоры Kepler способны положить начало широкой популяризации подобных служб, поскольку вместо современной концепции, предполагающей по одной видеокарте каждому игроку, будут использовать одну карту несколькими геймерами. Ожидаемая цена месячной подписки на все игры провайдера будет составлять порядка 10 долларов США.
САНТА-КЛАРА, Калифорния — 15 июня, 2011 — Российские ученые решили обратиться к суперкомпьютерам на базе GPU для решения научных задач, и сегодня Московский государственный университет имени М.В. Ломоносова оснащает свой суперкомпьютер «Ломоносов» графическими процессорами NVIDIA Tesla, благодаря чему он станет одной из самых быстрых вычислительных машин в мире.
Гибридное расширение «Ломоносова» состоит из 1554 графических процессоров NVIDIA Tesla X2070 и такого же числа четырехъядерных CPU, обеспечивая всю систему пиковой производительностью 1,3 петафлопс, что делает ее самым быстрым суперкомпьютером в России и одной из самых быстрых вычислительных систем в мире.
Суперкомпьютерные ресурсы МГУ используется в первую очередь для выполнения фундаментальных научных исследований, предполагающих ресурсоемкие вычисления. Среди таких задач масштабные работы по глобальному изменению климата и динамике мирового океана, постгеномной медицине, механизмам формирования галактик и др.
«Для наших исследований требуются огромные вычислительные ресурсы, и мы должны обеспечить необходимую производительность максимально эффективным способом»,— отметил Виктор Садовничий, академик РАН, ректор Московского государственного университета. «Единственно возможный способ добиться этих целей одновременно – использование гибридных вычислительных систем на базе GPU/CPU», добавил он.
Intel рассчитывает запустить первые Many Integrated Core (MIC) используя готовящийся к внедрению 22 нм техпроцесс, при этом планируется привлечь более 100 разработчиков для MIC до конца 2011 года.
Ожидается, что дополнительный акселератор микроархитектуры Intel MIC будет использоваться для сильно распараллеленных приложений в высокопроизводительных вычислениях, в таких сегментах как научные исследования и погодное моделирование. Но в отличие от AMD FireStream или NVIDIA Tesla, Intel хочет, чтобы их технология не заменила процессоры, а ускорила существующие приложения.
Intel настаивает, что х86-совместимость даст MIC уникальное преимущество. Кирк Скоген (Kirk Skaugen), вице-президент архитектурной группы и главный менеджер группы датацентра Intel, во время своего доклада на Intel Developer Forum сказал, что MIC будет, как бы, сопроцессором, на котором вы сможете использовать те же компиляторы, те же инструменты, тот же VTune. При этом вычислительная мощность составит порядка 90% самых производительных мировых компьютеров.
Он также пообещал, что когда вы запустите компилятор следующего поколения, он уже будет оптимально загружать ядра Intel, находящиеся в процессорах Xeon, и он будет оптимизировать загрузку на новых PCI-Express картах, которые будут иметь более чем 50 ядер изготовленных по 22 нм технологии.
А пока Intel представила тестовую платформу под названием Knights Ferry, предназначенную для отбора разработчиков и планы по увеличению числа разработчиков, имеющих необходимое оборудование, до сотни, к концу 2011 года.
Три вооружённых чипами NVIDIA суперкомпьютера оккупировали верхние строчки списка.
Ноябрьский список Top500 принёс ожидаемое первое место китайскому суперкомпьютеру Tianhe-1A, 2,7 петафлопа которому обеспечили вычислительные модули NVIDIA Tesla. Однако, он оказался не единственным GPU-ускоренным суперкомпьютером в верхних строчках списка. На третьем месте расположился предтеча Tianhe-1A, суперкомпьютер Nebulae, также оснащённый модулями Tesla, c общей производительностью в 1,27 петафлоп. Четвёртое место занял еще один новичок в списке, суперкомпьютер Tsubame 2.0 из Японии, в результат которого в 1,19 петафлоп основной вклад внесли процессоры NVIDIA Tesla.
Продукты компании Cray Inc продолжают удерживать половину верхней десятки списка, но такими темпами перевес скоро окажется не на их стороне и количественно.