Забытый пароль вскоре может перестать быть проблемой.
Развитие GPGPU-технологий осложнило жизнь системным администраторам и простым пользователям, заботящимся о защите своих данных: вскрытие пароля нормальной длины и сложности путём перебора, ранее считавшееся доступным лишь спецслужбам и группам хакеров, стало возможным почти для каждого — достаточно «натравить» на пароль современную видеокарту на базе логики AMD и NVIDIA. Программа oclHashcat, в отличие от специализированных GPGPU-утилит для вскрытия паролей баз данных и архивов RAR, является настоящим комбайном, умея подбирать хэши MD5, SHA1, NTLM, кэшированных паролей домена и паролей баз данных MySQL. Поддерживаются видеокарты как на базе AMD (OpenCL, требуется Catalyst 10.12 и ATI Stream SDK), так и NVIDIA (CUDA, требуется драйвер 260.хх и новее), программа работает в Windows и Linux.
Производительность перебора для современных карт составляет:
GeForce GTX 480: 1041 M c/s
GeForce GTX 580: 1217 M c/s
Radeon HD 5870: 1211 M c/s
Radeon HD 6970: 1575 M c/s
Интересно, что программа умеет использовать и несколько GPU одновременно в системах SLI/Crossfire (до 16, по заявлениям авторов). Будучи основанной на коде Hashcat, к программе могут подключаться словари аналогичного формата для дополнительного ускорения перебора. Лишь сложный консольный интерфейс отпугнёт желающих восстановить свой забытый пароль или узнать чужой.
Задействовать функции кодирования видео процессоров Sandy Bridge в известном редакторе.
Одним из новшеств архитектуры Sandy Bridge процессоров Intel Core iX второго поколения является наличие выделенных блоков в составе графического ядра для декодирования и кодирования видео в популярных форматах. Последняя функция под названием Quick Sync продемонстрировала неплохие результаты в обзорах, показав впечатляющие качество и скорость операций. Хотя ранее предполагалось, что данная функциональность будет доступна через универсальные APIвроде OpenCL, пока что единственный способ её использовать — использовать собственный Intel Media SDK 2.0, с библиотеками которого должны соединяться приложения. К выходу Sandy Bridge ряд разработчиков представил соответствующие приложения, но в основном это простенькие редакторы и конвертеры, рассчитанные на широкие массы конечных пользователей.
Для профессионалов Intel выпустила плагин для известного редактора Adobe Premiere Elements и Premiere Pro, позволяющий осуществлять экспорт проектов с аппаратным ускорением кодирования. Поддерживается кодирование видео в стандарты H.264 и MPEG-2, Intel обещает двух-трёхкратное ускорение для H.264 в сравнении с кодеками Adobe. Для работы плагина требуются 32- или 64-битная версия Windows 7, Adobe Premiere Elements версий 8-9 или Premiere Pro CS4-5, ну и сам процессор архитектуры Sandy Bridge, причём должно быть доступно встроенное графическое ядро — аппаратное ускорение будет недоступно при отключенном ядре или при запуске приложения на мониторе, обслуживаемом видеокартой.
В ожидании новых процессоров плагин можно проверить и на существующих, в программном режиме, для чего потребуется установить Intel Media SDK 2.0.
Пока что плагин предоставляется в демонстрационных целях, в будущем не исключено появление коммерческого продукта. Напомним, что в Premiere CS5 уже был реализован механизм использования аппаратного ускорения в Mercury Playback Engine, но он не ускоряет операции экспорта и финального кодирования, работает только через NVIDIA CUDA и то лишь для небольшого количества видеокарт.
Компания анонсировала низкопрофильную видеокарту для HTPC, с поддержкой стерео, Blu-ray и GPGPU.
Новый продукт компании под незамысловатым названием eH1 представляет собой дискретную низкопрофильную видеокарту с интерфейсом PCI-Express 2.0. Ранее VIA не продвигала видеокарт под своей маркой, оставляя эту задачу дочернему подразделению S3 Graphics.
В основе карты лежит, впрочем, продукт всё той же S3 Graphics — более чем годовой давности чип Chrome E5400. К штатным функциям поддержки Direct3D 10.1/OpenGL 3.1, VLD-ускорению декодирования H.264 и IDCT-ускорению для VC-1, OpenCL 1.0, поддержке двух дисплеев, подключаемых по HDMI 1.3, DisplayPort или DVI добавились (спасибо драйверам) поддержка OpenGL ES 2.0 и вывод стерео, вероятно в виде поддержки соответствующих режимов HDMI 1.4 для 3D-телевизоров.
Конкретная модель eH1 оснащена 512 Мб видеопамяти DDR-3 на 64-бит шине, выходами DVI Dual-Link и HDMI. TDP карты не раскрывается, но предусмотрен небольшой вентилятор на GPU. Драйверы предлагаются пока лишь для Windows Vista/7 и Windows XP, причём последняя поддерживается лишь в 32-разрядной ипостаси и лишена поддержки Blu-ray.
Основное назначение данной видеокарты — апгрейд для платформ Nano/EPIA самой VIA с целью подключения дополнительных мониторов и повышения производительности. Последнее, впрочем, выглядит маловостребованным — последние модели на чипсетах VX900 и VN1000 и так содержат интегрированное графическое ядро с полным комплектом функций для работы с видео. Цены и сроки появления в продаже не сообщаются. VIA также обещает в будущем возможность группировать несколько таких видеокарт для поддержки многомониторных конфигураций. Может быть мы увидим наконец и двухпроцессорную видеокарту компании.
После двухмесячного тестирования на кошечках программистах NVIDIA выпустила финальную версию пока что самого успешного GPGPU API CUDA 3.2. Об изменениях в новой версии CUDAуже писалось неоднократно, так что желающие опробовать её в деле могут сразу загрузить всё необходимое с сайта NVIDIA для разработчиков.
Одновременно вышли и новые отладочные драйверы видеокарт для разработчиков, традиционно, более новой версии, чем драйверы для конечных пользователей. Загрузить новые драйверы для основных платформ можно по ссылкам ниже:
Плюс прогноз применимости GPGPU для суперкомпьютеров.
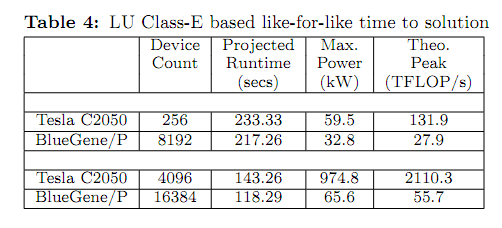
В этом году IBM публиковала два исследования, в которых сравнивалась производительность CPU и GPU в математических задачах. В первом случае центральный процессор IBM Power 7 опередил GeForce GTX 285, причём двухпроцессорная система на базе Intel Xeon показала лишь чуть меньший результат, во втором испытании модуль NVIDIA Tesla 2050 опередил всех соперников, но разрыв в производительности составил чуть более двухкратного для Power 7 и не дотянул до четырёхкратного над Xeon. И вот появилось новое исследование, от университетов Оксфорда и Ворвика, Великобритания, в котором системам на базе Xeon были противопоставлены модули Tesla разных поколений и пара «бытовых» видеокарт.
Хотя для исполнения на CUDA использованный тест NAS LU пришлось портировать с Fortran на C, результат представляет немалый интерес. Всего один четырёхъядерный процессор Xeon X5550, работающий на частоте 2,66 ГГц, смог показать лучший результат, чем GeForce 9800 GT с теоретической производительностью 500 GFLOPS. GeForce 8400 GS из-за ограниченного буфера памяти (256 Мб) смогла выполнить лишь один этап из трёх и показала ужасную производительность. Модули Tesla оправдали свою репутацию, но отрыв в производительности не превышал 10-кратного. Любопытно, что включение режима защиты памяти ECC на Tesla 2050 стоило ей 20 % производительности, в том числе из-за потери 16 % объема видеопамяти на контрольные суммы.
Британские учёные не могли хотя бы частично не подтвердить свою репутацию. На основе полученных данных они попытались спрогнозировать производительность суперкомпьютерных систем на базе Tesla, сравнив их предсказанную производительность с хорошо себя зарекомендовавшими системами BlueGene /P от IBM.
Согласно предсказанию, традиционный подход к построению суперкомпьютеров выиграет по соотношению фактической производительности на Ватт, и в конечном итоге — по быстродействию вообще. Впрочем, GPU уже сделали заявку на лидерство среди суперкомпьютеров, посмотрим, что сможет на неё ответить та же IBM.
CUDA останется основным API, поддерживаемым NVIDIA.
Глава NVIDIA Jen-Hsun Huang в интервью британскому отделению издания ZDNet ответил на вопросы о будущем GPGPU-технологий. Мы приводим выдержку высказанных им суждений:
NVIDIA активно поддерживает открытый стандарт OpenCL, тем более что Khronos Group в настоящее время возглавляет сотрудник компании. NVIDIA первой реализовала поддержку OpenCL, причём она всё еще считается лучшей в отрасли, и будет поддерживать OpenCL и дальше.
Технологии меняются очень быстро, производительность увеличивается четырёхкратно каждые два года, новые функции внедряются постоянно. В силу этого NVIDIA концентрируется на CUDA, не желая немедленно «выкатывать» новый общий стандарт. Тем более, что OpenCL такого внимания и не требует — там есть множество людей, в том числе из IBM, AMD, Intel, и NVIDIA не нужно тащить всё в одиночку.
CUDA получил большее распространение, чем OpenCL, в силу большей истории и инвестиций в разработку, большего числа работающих с ним людей, большего качества инструментов разработки, компилятора, надёжности рабочей среды.
NVIDIA не пытается каким-то способом полностью заменить CPU или нарушить их работу. Операционные системы и офисные приложения будут продолжать работать на CPU — но будет возможно прибегнуть к силе GPU для того, чтобы «проломить» определённые задачи.
Будущее за гетерогенной средой, в которой встретятся нарастившие мощь векторной обработки данных CPU и GPU с параллельной обработкой данных, научившиеся решать более сложные типы задач. В такой среде все приложения будут работать невероятно быстро.
Сейчас ситуация с приложениями такая, что они не работают, не работают, а потом раз — и работают очень быстро. Технологии вроде виртуальной памяти и синхронизации данных в памяти облегчат программирование. В целом будет лучше, если приложения будут работать сразу, пусть и лишь в три раза быстрее. Затем можно будет заниматься оптимизацией.
Сейчас графические процессоры лучше всего работают с одним приложением, так устроен их конвейер, следствие stateful-подхода. К примеру, одна большая программа исполняется на многих GPU. В будущем будет иная ситуация: множество приложений, использующих один GPU. NVIDIA работает над тем, чтобы обеспечить возможность использования обоих подходов.
В будущей архитектуре сервер с одним модулем Tesla сможет одновременно предоставить игровой ускоритель для сеанса геймера, Quadro-ускоритель для сеанса дизайнера автомобиля и GPGPU-ускоритель для сеанса высокопроизводительных вычислений. Можно будет одновременно заниматься вычислениями и визуализацией в отдельном «облаке», получая высококачественную картинку на экран компьютера, планшетного ПК или телефона.
Ключ к созданию подобных архитектур — отказ от копирования данных туда-сюда. NVIDIA совместно с InfiniBand разрабатывает решение, которое позволит избежать постоянного копирования данных из системной памяти в видеопамять и обратно. Это позволит частично снять остроту проблемы полосы пропускания каналов связи, хотя всё равно всегда будут требоваться как можно более быстрые методы передачи данных.
Будем надеяться, что в погоне за раскрывающими перспективами облачных сред и распределённых вычислений компания не забудет совсем про сегмент, собственно, видеокарт для конечных ПК.
Модульный сервер позволяет установить до 16 GPU-карт PCI-Express.
Компания Dell для своих новых серверов линейки PowerEdge C Series предусматривает специальный блок расширения PowerEdge C410x, представляющий собой платформу для установки карт с интерфейсом PCI-Express x16.
Данный модуль высотой 3U позволяет установить 16 GPU-карт (10 спереди и 6 сзади) с TDP до 225 Вт каждая, и рассчитан прежде всего на установку GPGPU модулей NVIDIA Tesla M2050 с 448 ядрами CUDA архитектуры Fermi и тремя или шестью гигабайтами ECC GDDR-5 памяти.
Питание обеспечивают 4 блока мощностью 1400 Вт каждый, за охлаждение отвечают восемь 92-мм вентиляторов. Блоки питания и вентиляторы поддерживают отказоустойчивость и «горячую» замену. Модули карт поддерживают добавление на ходу, но не замену.
Совокупная вычислительная мощность платформы — более 16 000 GFLOPS и может быть разделена между 8 серверами PowerEdge C Series, подключаемыми с помощью внешних соединений PCI-Express I-PASS к специальным интерфейсным картам NVIDIA HIC. Программная поддержка решения пока реализована лишь в Red Hat Enterprise Linux.
Dell уже поставила подобную систему как часть суперкомпьютера Lincoln для Национального суперкомпьютерного центра США, с вычислительной производительностью в 47 TFLOPS. Но подобный продукт, без сомнения, найдёт спрос и у корпоративных потребителей в области решений для виртуализации, поскольку и Microsoft, и VmWare уже объявили, что следующее поколение их продуктов будет поддерживать виртуализацию графического процессора, что позволит исполнять «тяжёлые» графические приложения в виртуальных машинах. Причём предварительная версия технологии Microsoft RemoteFX уже доступна в открытом для бета-тестирования Windows Server 2008 R2 SP1 Release Candidate.
Новая версия среды разработки графических и GPGPU-приложений.
NVIDIA выпустила версию 1.5 своего набора средств для разработки графических и GPGPU-приложений Parallel Nsight, ранее известного как Nexus. Новая версия поддерживает интеграцию в Microsoft Visual Studio 2010, совместима с проектами CUDA Toolkit 3.2, содержит обновлённый отладчик CUDA-программ с поддержкой новых видеокарт GeForce и Quadro на базе Fermi, полностью поддерживает Direct3D 11 и DirectCompute и содержит ряд других изменений. Загрузить дистрибутив комплекта можно с сайта NVIDIA для разработчиков по ссылкам ниже:
Для получения одной бесплатной лицензии на стандартную версию пакета требуется регистрация на специальном сайте. Расширенная лицензия (с дополнительными функциями, такими как визуальный анализатор производительности и удалённая отладка) стоит USD 349 на год.
Также NVIDIA обновила документацию для разработчиков игр по обеспечению совместимости с системами стереовидения NVIDIA 3D Vision (PDF, ~1 Мб) и 3D Vision Surround (PDF, ~2 Мб). Будем надеяться, что игроделы будут ей следовать, и мы увидим в будущем больше игр с корректно работающим стереорежимом.
Еще один, к счастью, неудавшийся пример патентования слишком общих идей.
Сейчас использование мощностей графических процессоров для операций с видео стало обыденностью. Многие владельцы современных видеокарт на базе NVIDIA воспользовались продуктами от Badaboom или MotionDSP с данной функциональностью. Тем удивительнее стало обнаружение факта, что на подобные технологии кем-то получен патент, и этот кто-то — Microsoft. Буквально на днях Бюро по регистрации патентов и торговых марок США утвердило за компанией патент за номером 7,813,570 под многообещающим заголовком «Accelerated video encoding using a graphics processing unit».
Первые реакции на выдачу такого патента были ожидаемы — попытка компании-монополиста наложить лапу на перспективный рынок, шаг против прогресса, заговор против производителей GPU… Однако, изучение содержания патента позволяет существенно снизить накал страстей.
Прежде всего, заявка на патент была отправлена в Бюро… 22 октября 2004 года. В ту пору возможность использования графических процессоров для общих вычислительных задач еще была предметом научных исследований. К примеру, в 2004 году университетом Стэнфорда была выпущена программа GPUBench, как иллюстрация к обсуждению перспектив GPGPU перед выставкой SIGGRAPH 2004 (обсуждавшиеся тогда вопросы сегодня могут вызвать лёгкую улыбку).
Во-вторых, указанный патент покрывает лишь случай использования GPU для выполнения операции определения движения — нахождения движущихся объектов в кадре и расчёта векторов движения и информации, необходимой для последующего восстановления видео при воспроизведении, как это определено в стандартах MPEG-1/2. Все остальные операции выполняет центральный процессор. Современные программы кодирования с применением GPGPU-технологий не выделяют какие-то этапы кодирования, используя GPU как математический сопроцессор для всех или почти всех операций с видеопотоком. Ну и, согласно тексту патента, работа с видео должна была осуществляться путём помещения кадров в текстуры, обработке их с помощью пиксельных и вершинных шейдеров образца Direct3D 9.0 и использованием Z-буфера для хранения промежуточных результатов операции. Нынешнее программное обеспечение видеокодирования с функциями GPGPU использует высокоуровневые интерфейсы вроде CUDA или ATI Stream.
В целом, заявка на пресловутый патент, вероятно, была подана в рамках разработки следующих версий приложений Windows Movie Maker/Movie Encoder для будущей операционной системы Longhorn, но проект умер вместе с самим Longhorn. К настоящему моменту Microsoft пришла к собственному GPGPU API DirectCompute в составе DirectX 11 и врядли нуждается в патентовании схемы использования аппаратного ускорения шестилетней давности. Так что история с патентом за номером 7,813,570 является лишь иллюстрацией неповоротливости и ограниченности патентной системы, с непоправимым опозданием «защитившей» права на давно потерявшую актуальность разработку.
NVIDIA анонсировала следующую версию средств для разработки CUDA Toolkit для API CUDA. В новой версии 3.2, как сообщается, разработчиков ожидают следующие новшества:
Новые библиотеки CUSPARSE (для операций с матрицами) и CURAND (генератор случайных чисел).
Улучшение производительности библиотек CUFFT и CUBLAS на архитектуре Fermi.
В состав CUDA Toolkit теперь включены библиотеки для работы с видео в формате H.264.
Добавлена поддержка новых продуктов Quadro и Tesla с объёмом буфера более 4 Гб, включая отладку на таких конфигурациях.
Отладка многопроцессорных конфигураций в cuda-gdb и Parallel Nsight.
Поддержка Fermi в cuda-memcheck.
Поддержка компилятора Intel C в 64-битных версиях Linux в NVCC.
Поддержка функций malloc() и free() в ядре CUDA-программы.
nvidia-smi поддерживает выдачу нескольких новых счётчиков производительности, включая загрузку GPU.
Доступ к предварительной версии CUDA Toolkit 3.2 осуществляется через бесплатную регистрацию на сайте NVIDIA для разработчиков.