Появились новые детали об архитектуре GP100
Представленный графический процессор GP100 от NVIDIA несомненно обладает огромной производительностью, но не до конца понятно, как он устроен, и мы предлагаем в этом разобраться.
Для начала нужно отметить, что GP100 является многочиповым модулем, подобным AMD Fiji. Он состоит из большого ядра GPU, четырёх стеков памяти и кремниевой пластины, действующей в качестве подложки для GPU и стеков памяти, и позволяющей NVIDIA соединять все компоненты микроскопическими дорожками. Процессор GP100 содержит 4096-битную память HBM2 с типичной пропускной способностью до 1 ТБ/с. В представленной модели пропускная способность памяти составляет 720 ГБ/с.

Структура GP100 довольно похожа на прочие GPU NVIDIA за исключением изменений в двух главных интерфейсах — шине и памяти. Хост интерфейс PCI-Express gen 3.0 x16 подключает GPU к вашей системе, а GigaThread Engine разделяет нагрузку между шестью графическими процессорными кластерами. Восемь контроллеров памяти обеспечивают шину памяти в 4096 бит, а новый компонент High-speed Hub связывает четыре порта NVLink. В настоящее время неизвестно, каждый ли порт имеет пропускную способность в 80 ГБ/с (на направление) или все 4 порта вместе.
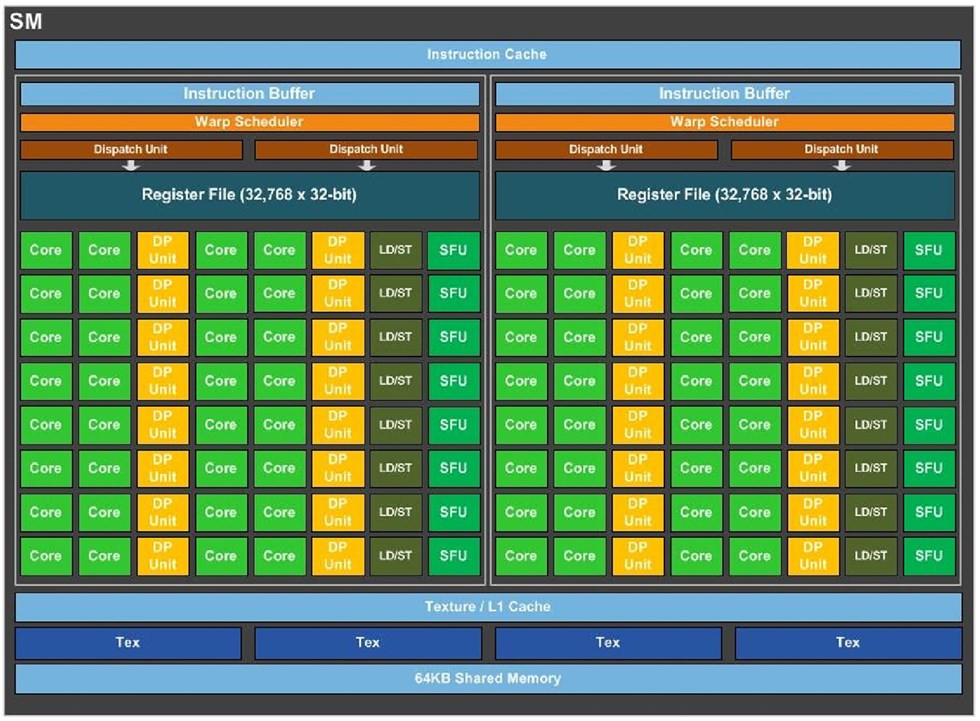
Шесть графических кластеров GP100 практически независимы, они имеют собственные фронт- и бэкэнды рендера. В архитектуре Pascal, как минимум в GP100, каждый кластер состоит из 10 потоковых мультипроцессоров (SM), основных рабочих единиц GPU. Каждый же SM содержит 64 ядра CUDA. Таким образом, каждый кластер содержит 640 ядер CUDA, а всего в GP100 их 3840 штук. Ещё одним важным параметром является число TMU, которых в этом GPU 240 штук. В ускорителе Tesla P100 NVIDIA оставила активными 56 из 60 мультипроцессоров.
Архитектура Pascal спроектирована для работы на высоких частотах. В частности, P100 работает на номинальной частоте 1328 МГц с 1480 МГц в режиме Boost и тепловыделением на уровне 300 Вт. Эта цифра может вас напугать, но не стоит забывать, что чипы памяти были перемещены на GPU, так что это суммарный TDP всех микросхем.
Последним новшеством, заслуживающим вниманием, стала шина NVLink. Это средство связи, разработанное NVIDIA, которое похоже на шину QPI от Intel или HyperTransport от AMD. Каждая линия NVLink обеспечивает пропускную способность в 80 ГБ/с на направление, что обеспечивает настоящую виртуализацию памяти между разными GPU.
Как отмечалось ранее, первые видеокарты на базе Pascal должны появиться в начале лета.